



caltech101 28x28 and 16x16 silhouettes
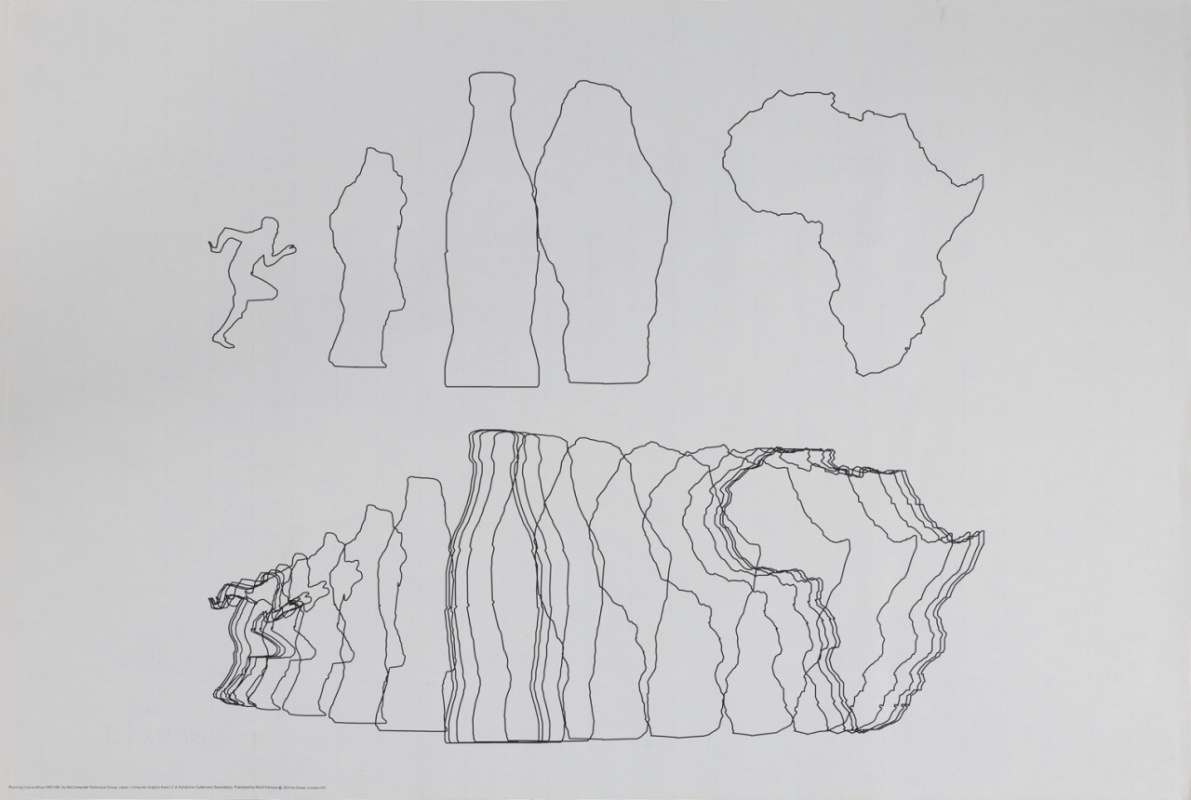
RUNNING COLA IS AFRICA 1967/68 - A computer graphic, No 3 in the Metamorphoses Series by the Computer Technique Group from Japan. Idea by Masao Komura (product designer) data by Makoto Ohtake (architectural designer) programme by Koji Fujino (systems engineer) - A computer algorithm converts a running man into a bottle of cola, which in turn is converted into the map of Africa. Programmed in Fortran IV on IBM 7090 and drawn on Calcomp 563 plotter.





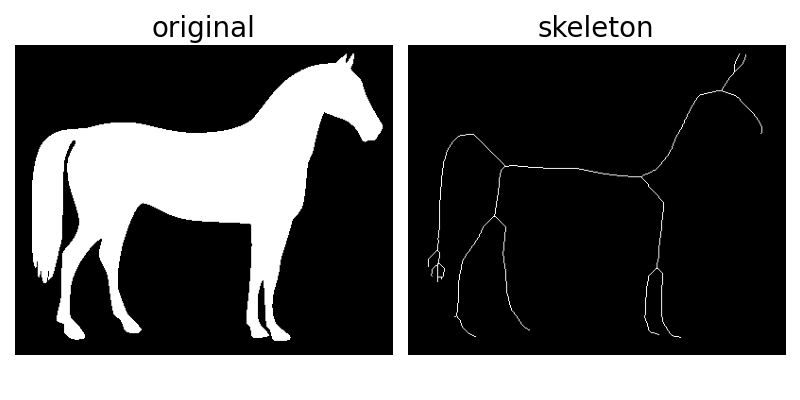
https://scikit-image.org/docs/stable/auto_examples/edges/plot_skeleton.html


Malen nach zahlen

a baby elephant standing next to an adult elephant in the dirt next to a wired
enclosure.
a young elephant standing next to a larger elephant
a baby elephant and a larger adult elephant behind it.
two elephants in their enclosure with focus on the baby elephant.
a baby elephant is scratching its trunk across some rocks.

two giraffes standing next to each other in a zoo.
two giraffes, one adult, one young walk in a fenced area as another lays on the ground.
a couple of giraffe in a fenced in area.
two giraffes are standing in an enclosed area.
some giraffes hanging out together in a fenced area.
In 2015 I scraped 4chan because I thought it would be a perfect source for a dataset.

.png)

Fabio Lanzoni https://arxiv.org/abs/1202.6429
In response to concerns about the use of the "Lenna" image—a cropped Playboy centerfold widely utilized in image processing research—some researchers have sought alternative test images. In 2013, mathematicians Deanna Needell and Rachel Ward introduced a photograph of male model Fabio Lanzoni as a substitute. They obtained permission from Lanzoni's agent to use his likeness, aiming to address gender issues in the field by providing a male counterpart to the Lenna image.

data > compute
https://www.youtube.com/watch?v=a42key59cZQ
WWCGPTD
"Segmentation Stories"
Create diptychs: one image showing the original photo, another showing human-drawn segmentation boundaries
Photograph scenes that deliberately challenge early segmentation categories
Document objects that weren't included in early datasets but are ubiquitous today (like smartphones)
"Training Data Lineage"
Track specific objects through different dataset eras
Show how segmentation style evolved from crude boundaries to fine-grained details
Highlight how different humans segment the same scene differently
"The Human Touch in Machine Vision"
the hand drawn outlines of eg labelme and others
segmented stories
segmented context
braille context
children book
feeling data

color schedule for one plot




















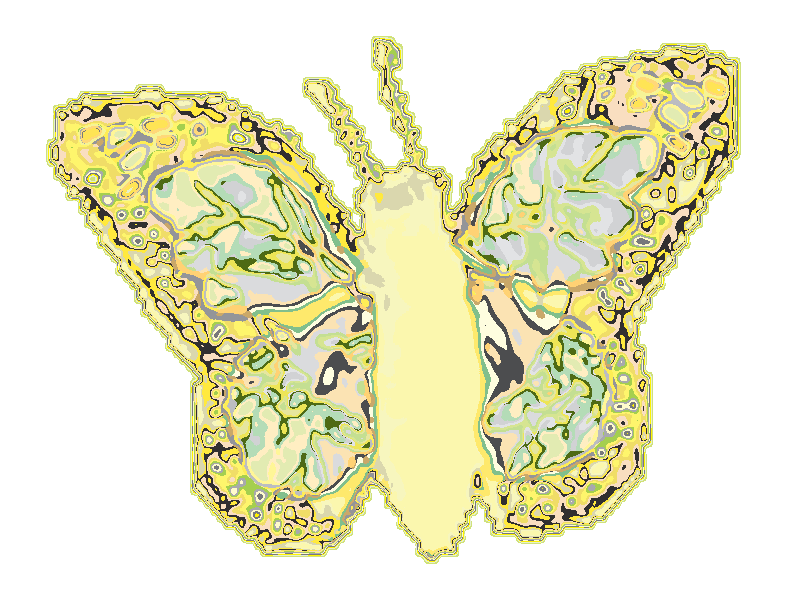
Butterfly no.21




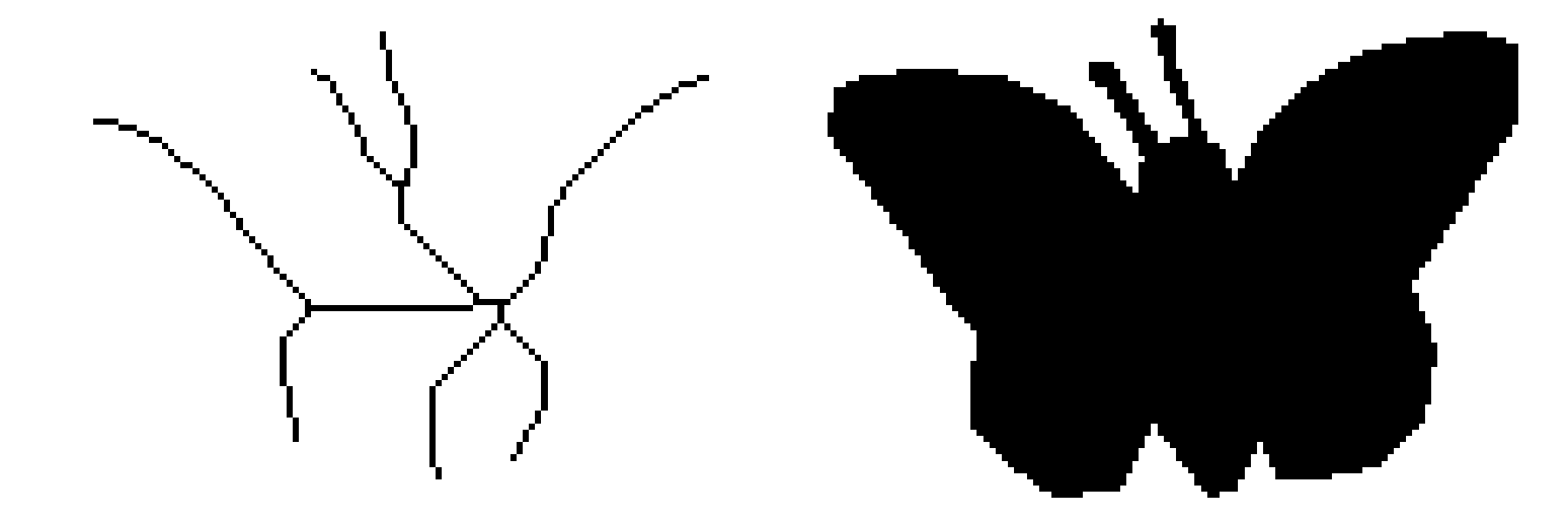
postcards for #pptx 2024
.jpg)
Vintage datasets
Coil 100
CalTech 101
CalTech 256
LabelMe 12 50k
VOC2008
Pascal VOC2010
VOC2012
MICC-Flickr 101
MS Coco
Microsoft Research Cambridge (MSRC) Object Recognition Database
Berkeley Segmentation Dataset (BSDS300 und BSDS500)
Weizmann Horse Dataset
ETHZ Shape Classes Dataset
Caltech-UCSD Birds 200 (CUB-200)
Stanford Background Dataset
SIFT Flow Dataset
Graz-02 Dataset
CMU-Cornell iCoseg Dataset
Fashionista Dataset
Daimler Pedestrian Segmentation Benchmark Dataset
Lotus Hill Dataset
Caltech Silhouettes Dataset
PD12M
4chan dataset
Imagenet
ObjectNet
CIFAR-100
MPEG-7 Core Experiment CE-Shape-1 Test Set
>
The MPEG-7 Core Experiment CE-Shape-1 dataset, released around 2000, was groundbreaking for its time as one of the first standardized datasets specifically designed for shape-based object recognition. Unlike contemporary datasets that focused on natural images, MPEG-7 specialized in binary shape images - essentially silhouettes of objects viewed from a single perspective. What made this dataset particularly unique was its focus on testing shape descriptors' robustness to various transformations. It contains 70 different object classes, with 20 samples per class, where each sample might represent the same object under different conditions like rotation, scaling, or elastic deformation. This methodical approach to testing shape invariance was crucial for developing and evaluating shape matching algorithms that could recognize objects regardless of these transformations. The dataset became a standard benchmark for evaluating shape descriptors and similarity measures, helping establish important metrics for shape-based recognition tasks. While it might seem simple by today's standards, its carefully curated collection of shape variations played a vital role in advancing our understanding of shape representation and matching in computer vision.
Caltech 101
>
Caltech 101 dataset, released in 2003 by Fei-Fei Li, Marco Andreetto, and Marc 'Aurelio
Ranzato
Each image in the dataset comes with annotated contours that outline the object of interest,
making it groundbreaking for its time. The dataset contains 9,146 images across 101 object categories (plus
a background class), with each image accompanied by these hand-annotated object segmentations.
This annotation of object outlines was a significant innovation that helped advance both object recognition
and segmentation tasks in computer vision. While many earlier datasets existed for object recognition,
Caltech 101's inclusion of object contours opened new possibilities for studying shape-based recognition and
segmentation algorithms. This approach to dataset annotation became influential and helped establish
standards for future computer vision datasets.
caltech skeletons

🐊

🐬

🐘

🐢

🦩

🦘

🐙

🕊️

🐓

💦🐎

⭐

🐈
ant,42,🐜
bass,54,🐟
beaver,46,🦫
brontosaurus,43,🦕
buddha,85
butterfly,91,🦋
crab,73,🦀
crayfish
crocodile,50,🐊
dalmatian
dolphin,65,🐬
dragonfly
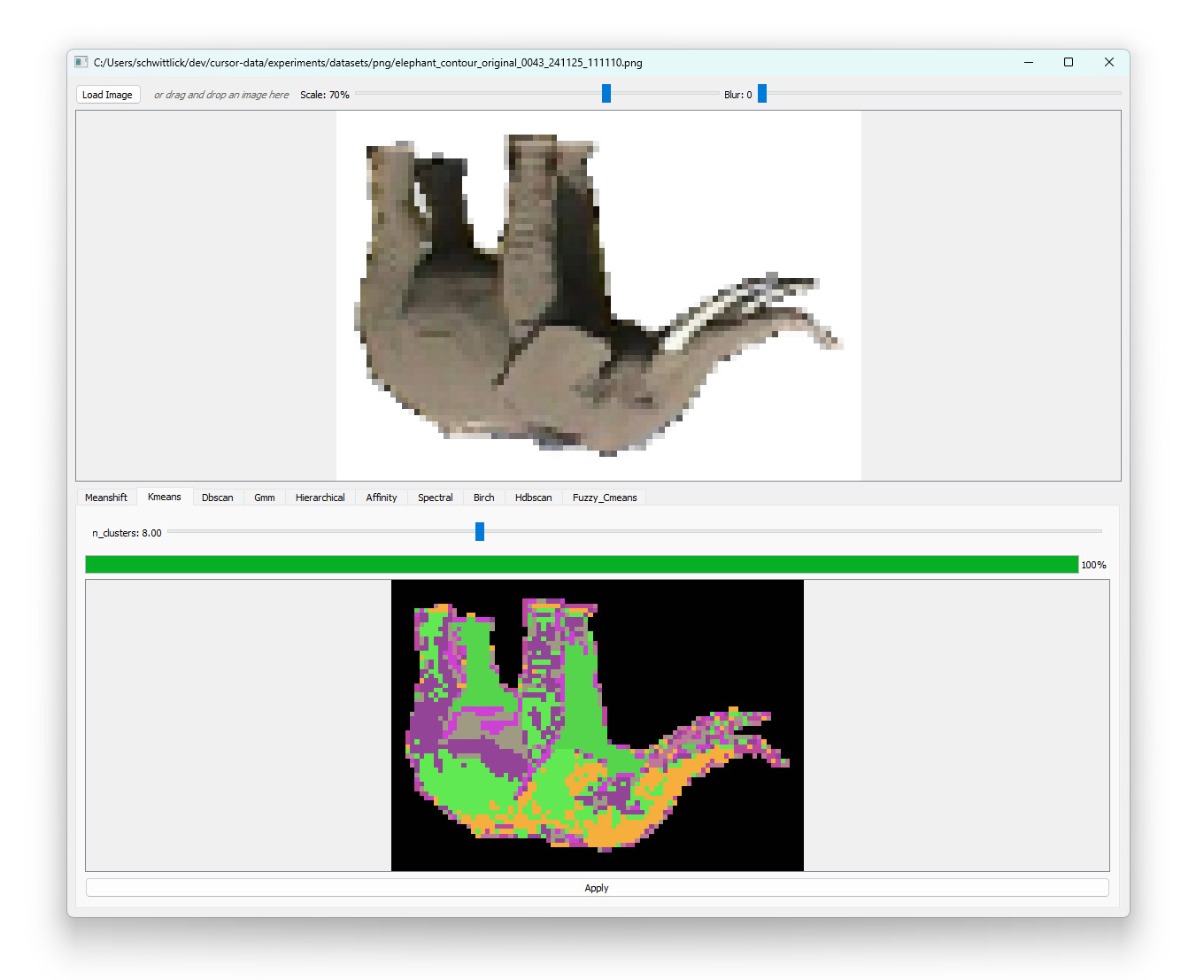
elephant,64,🐘
emu
flamingo,67,🦩
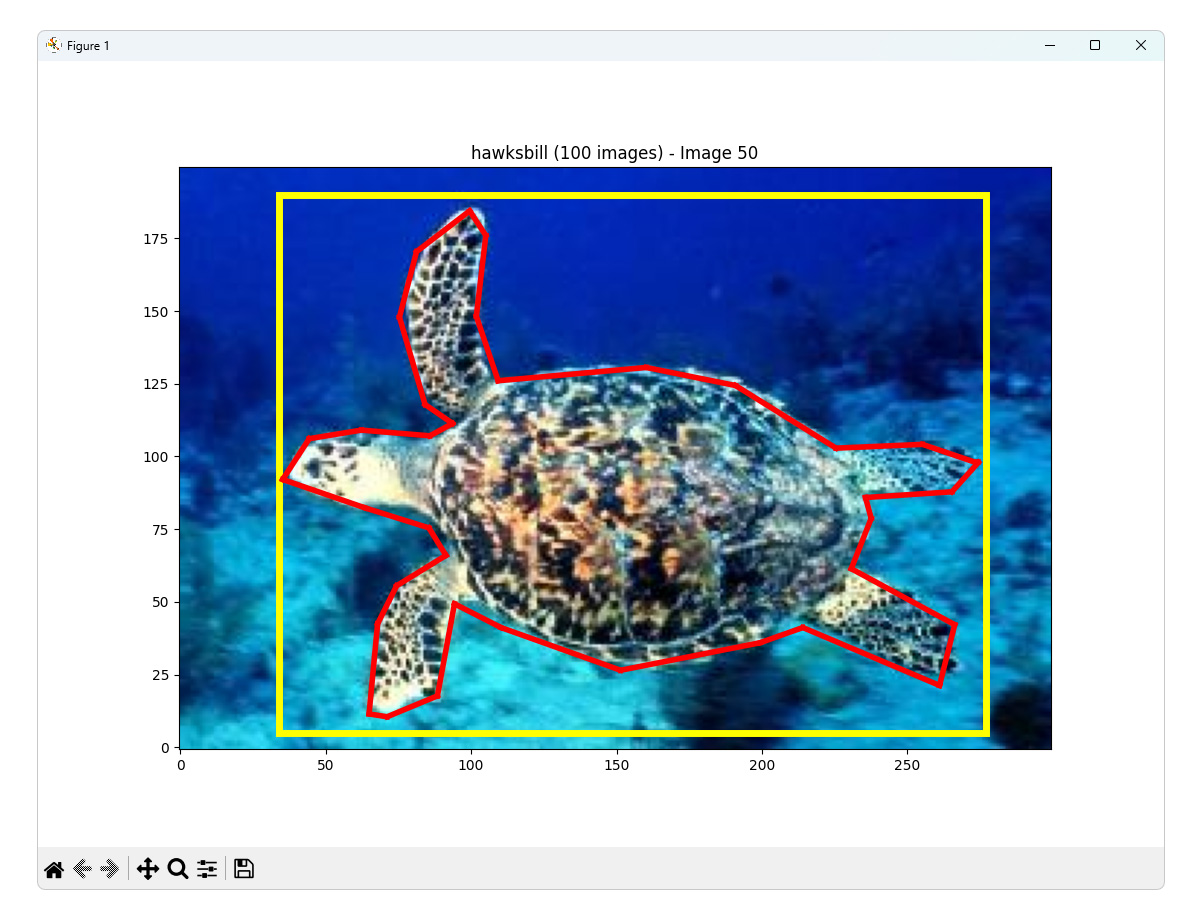
hawksbill,100,🐢
hedgehog,54,🦔
ibis
kangaroo,86,🦘
leopards,200,🐆
llama,78,🦙
lobster,41,🦞
mayfly
octopus,35,🐙
okapi
panda,38,🐼
pidgeon,45,🕊️
rhino,59,🦏
rooster,49,🐓
scorpion,84,🦂
sea horse
starfish,86,⭐
wild cat,34,🐈

epaper version ⮕ here
🦋 wip




Raspberry Pi, VA3200-QAA & Saltz board, custom framing,

Early tests 2021

preview rendering


experiments

Inspired by the work of Lorna Mills